This service allows you to convert ISO Latin 1, UTF-8, UTF-16, UTF-16LE or Base64 text to a hexadecimal value and vice versa.
UTF stands for Unicode Transformation Format and is a variable-width (1 to 4 bytes) encoding that can represent every character in the Unicode character set.
Example 1:
The Chinese character for "dragon" is
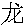
The Unicode for this character is: U+9F99
If you convert this Chinese character with this tool, the hexadecimal value will be:
- Chinese character for "dragon" in ISO Latin 1 encoding: ISO Latin 1 should not be used for Asian texts
ISO Latin 1 or ISO 8859-1 is a single-byte encoding that can represent the first 256 Unicode characters
U+0000 to U+00FF.
ISO Latin 1 and UTF-8 both encode ASCII exactly the same way.
- Chinese character for "dragon" in UTF-8 encoding, hexadecimal value = e9be99
UTF-8 is a multibyte encoding that can represent any Unicode character in 1 to 4 bytes:
- ASCII characters (U+0000 to U+007F) take 1 byte:
- Code points U+0080 to U+07FF take 2 bytes:
The Most Significant Byte (MSB) always start with 110.
The next byte always start with 10.
- Code points U+0800 to U+FFFF take 3 bytes:
The Most Significant Byte (MSB) always start with 1110.
The next bytes always start with 10.
- Code points U+10000 to U+10FFFF take 4 bytes:
The Most Significant Byte (MSB) always start with 11110.
The next bytes always start with 10.
It is recommended to use UTF-8 for Western texts (English, French, German, etc) where ASCII is predominant, but not for Asian texts.
- Chinese character for "dragon" in UTF-16 encoding, hexadecimal value = 9f99
The Most Significant Byte (MSB) is the left byte (9f) and the Least Significant Byte (LSB) is the right byte (99).
UTF-16 is a multibyte encoding that can represent any Unicode character in 2 bytes or 4 bytes:
- Code points U+0000 to U+FFFF take 2 bytes
- Code points U+10000 to U+10FFFF take 4 bytes
It is recommended to use UTF-16 for Asian texts (Chinese, Korean, Japanese, etc) where ASCII is not predominant, but not for Western texts.
- Chinese character for "dragon" in UTF-16LE, hexadecimal value = 999f
UTF-16LE is the same as UTF-16 but the LE form uses Little-Endian byte serialization (Least Significant Byte first)
Example 2:
This tool also converts Base64 encoded texts into hexadecimal values.
The word "hello" converted into Base64 is "aGVsbG8=" using the Base64 encoder and decoder.
The Base64 text "aGVsbG8=" converted into a hexadecimal value is "68656c6c6f".
Example 3:
The hexadecimal values in example 1 and 2 can also be converted back to its original text but make sure the correct "Text encoding" is selected.
For example the Chinese character for "dragon" in UTF-16 encoding converted into hexadecimal is 9f99.
If you convert it back but instead you select "Text encoding" = UTF-16LE, you get the wrong result.
Convert ISO Latin 1, UTF-8, UTF-16, UTF-16LE or Base64 text to hex and vice versa input:
|
|